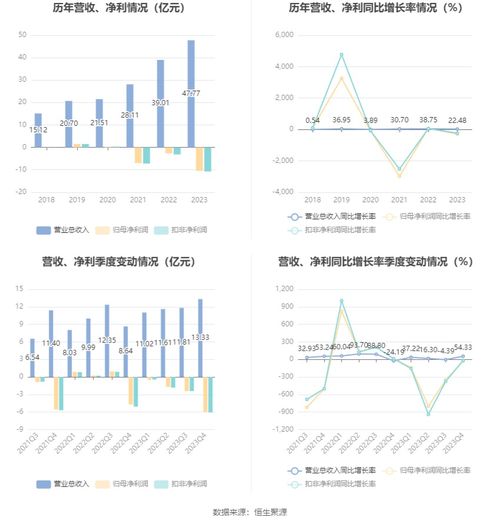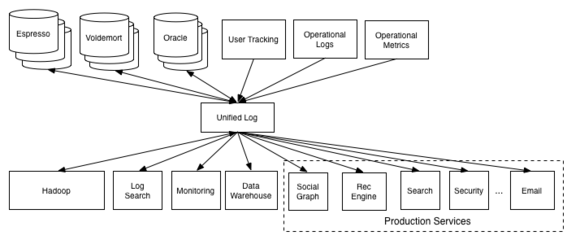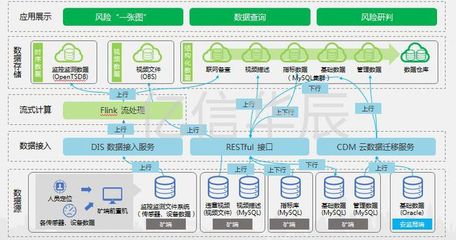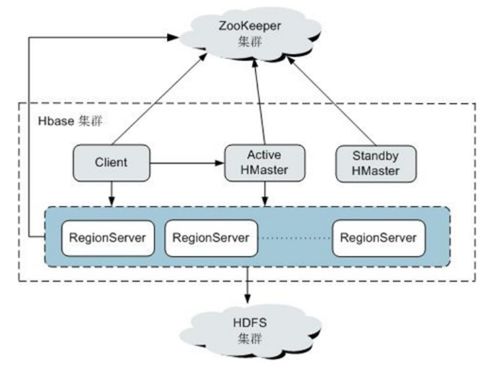
随着数据量的急剧增长和业务需求的日益复杂,大数据服务组件的规划与部署成为企业数字化转型的关键环节。其中,数据处理和存储服务是构建高效、可靠大数据平台的核心。本文将系统探讨大数据服务组件的整体规划策略,并重点阐述数据处理与存储服务的部署方案,以助力企业实现数据驱动的业务价值。
一、大数据服务组件整体规划
大数据服务组件的规划应以业务需求为导向,结合技术成熟度、可扩展性和成本效益进行综合考量。核心组件包括数据采集、数据处理、数据存储、数据分析和数据可视化等模块。在规划阶段,需明确各组件的功能边界、交互协议以及容错机制,确保系统的高可用性和易维护性。同时,采用分层架构设计,如Lambda架构或Kappa架构,能够有效平衡实时与批量处理的需求。
二、数据处理服务规划与部署
数据处理服务负责对原始数据进行清洗、转换、聚合和计算,以生成可供分析的高质量数据。其规划需关注以下方面:
- 处理引擎选择:根据业务场景,选用合适的处理框架,如Apache Spark用于复杂批量计算,Apache Flink用于低延迟流处理,或Apache Storm用于高吞吐实时处理。
- 流水线设计:构建端到端的数据处理流水线,包括数据接入、预处理、特征工程和模型训练等环节,并采用自动化调度工具(如Apache Airflow)管理任务依赖。
- 资源管理:通过YARN、Kubernetes等资源调度器,动态分配计算资源,提升集群利用率。部署时,需配置监控告警系统,实时追踪作业性能与异常。
三、数据存储服务规划与部署
数据存储服务需满足多模态数据的持久化需求,并提供高效的读写能力。规划要点包括:
- 存储架构设计:采用分层存储策略,结合热、温、冷数据的特点,选择不同类型的存储系统。例如,使用HDFS或云对象存储(如AWS S3)作为数据湖基础,NoSQL数据库(如HBase、Cassandra)支持高并发访问,而数据仓库(如ClickHouse、Snowflake)优化分析查询。
- 数据治理:实施元数据管理、数据血缘追踪和数据生命周期策略,确保数据的一致性、安全性与合规性。部署时,需配置备份与容灾机制,如跨地域复制和快照技术。
- 性能优化:通过数据分区、索引构建和缓存技术提升查询效率,同时监控存储容量与I/O性能,及时进行横向扩展。
四、集成与运维考量
数据处理与存储服务的部署需注重组件间的集成与整体运维。利用容器化技术(如Docker)和编排工具(如Kubernetes)可实现快速部署与弹性伸缩。建立统一的日志收集、性能监控和故障诊断体系,结合CI/CD流水线,保障服务的持续交付与稳定运行。
大数据服务组件的规划与部署是一个系统性工程,数据处理和存储服务作为基石,其设计需兼顾灵活性、可靠性与成本控制。通过科学的架构选型和细致的运维管理,企业能够构建出支撑业务创新的大数据平台,释放数据潜能,驱动智能决策。