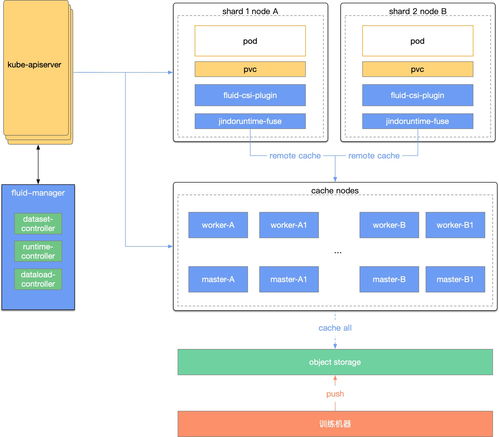
随着人工智能技术的快速发展,数据处理和存储服务在现代企业架构中扮演着至关重要的角色。作业帮作为国内领先的教育科技公司,其检索服务每天需要处理海量的用户查询和内容匹配请求。为了提升服务性能和资源利用率,作业帮选择了基于Fluid的计算存储分离架构,实现了数据处理与存储服务的深度优化。
一、背景与挑战
作业帮检索服务作为核心业务模块,需要快速响应用户的搜索请求,并提供准确的内容推荐。在传统架构中,计算节点和存储节点紧密耦合,导致了以下问题:
- 资源分配不均衡:计算密集型任务和存储密集型任务争夺同一资源池,导致系统瓶颈频现。
- 扩展性受限:数据量激增时,难以灵活扩展计算或存储资源。
- 运维成本高:数据迁移和节点维护操作复杂,影响服务可用性。
二、Fluid计算存储分离架构的优势
Fluid是云原生场景下的开源项目,专注于大数据和AI场景中的数据编排和加速。作业帮通过引入Fluid,实现了以下关键优化:
- 解耦计算与存储:计算节点和存储节点独立扩展,提升了系统的灵活性和资源利用率。
- 数据本地化加速:通过缓存和预加载机制,Fluid将常用数据缓存到计算节点本地,大幅降低了数据访问延迟。
- 统一数据管理:Fluid提供了统一的数据抽象层,支持多种存储后端(如HDFS、OSS、Ceph等),简化了数据运维流程。
三、实践方案与实施步骤
作业帮在检索服务中实施Fluid架构的主要步骤包括:
- 环境准备:部署Kubernetes集群,并安装Fluid组件。
- 数据集定义:通过Fluid的Dataset资源定义需要加速的数据集,并关联底层存储系统。
- 缓存策略配置:根据业务需求设置缓存大小、预热策略和数据淘汰规则。
- 计算任务调度:利用Fluid的Runtime(如AlluxioRuntime)将数据缓存到计算节点,并通过亲和性调度确保任务在数据本地节点执行。
四、成果与收益
通过基于Fluid的计算存储分离实践,作业帮检索服务取得了显著成效:
- 性能提升:数据访问延迟降低约40%,检索服务的平均响应时间缩短了30%。
- 成本优化:存储和计算资源独立扩展,避免了过度配置,资源利用率提升25%以上。
- 运维简化:数据管理操作自动化,减少了人工干预,系统稳定性显著增强。
五、未来展望
未来,作业帮计划进一步探索Fluid在更多业务场景中的应用,例如结合AI训练任务和多租户数据隔离。同时,团队将持续优化缓存策略和数据预取算法,以应对日益增长的数据处理需求。
基于Fluid的计算存储分离架构为作业帮检索服务的数据处理和存储提供了高效、灵活的解决方案。这一实践不仅提升了系统性能,还为后续的技术演进奠定了坚实基础。