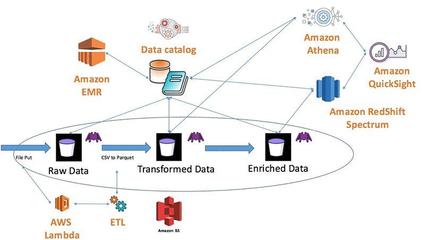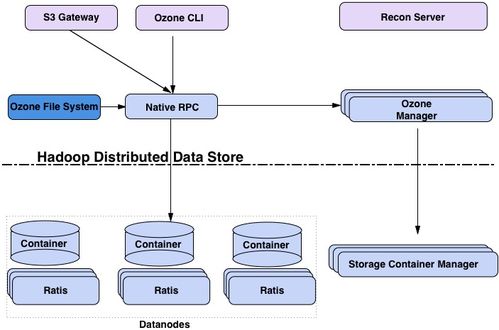
Apache Ozone 是一个分布式的、可扩展的对象存储系统,专为大数据和云原生环境设计。它作为 Apache Hadoop 生态系统的一部分,提供了高效的数据处理和存储服务,能够处理海量数据并支持多种工作负载。
1. 核心架构与组件
Ozone 采用分层架构,主要包含以下核心组件:
- Ozone Manager (OM):负责管理命名空间、元数据以及访问控制,确保数据的一致性和安全性。
- Storage Container Manager (SCM):管理存储容器(Storage Containers),处理数据块的分配、复制和存储节点管理。
- DataNodes:实际存储数据的节点,支持块和对象存储,并通过容器化方式优化资源利用。
Ozone 支持多租户架构,允许用户通过桶(Buckets)和卷(Volumes)组织数据,同时提供与 HDFS 的兼容性,便于现有 Hadoop 应用无缝迁移。
2. 数据处理能力
Apache Ozone 通过集成大数据工具(如 Apache Spark、Hive 和 Presto)提供强大的数据处理能力:
- 数据湖支持:Ozone 可以作为数据湖的底层存储,支持结构化、半结构化和非结构化数据的统一管理。
- 流处理和批处理:通过与 Apache Kafka 和 Flink 等流处理框架集成,Ozone 能够处理实时数据流和批量作业。
- 数据访问接口:提供 REST API、S3 兼容接口和 Hadoop 文件系统接口,方便用户通过多种方式读写数据。
3. 存储服务特性
Ozone 的存储服务设计注重高可用性、可扩展性和成本效益:
- 可扩展性:支持横向扩展,可轻松添加存储节点以处理 PB 级数据,而无需停机。
- 数据持久性与一致性:通过多副本和擦除编码(Erasure Coding)技术确保数据可靠性和存储效率。
- 安全机制:集成 Kerberos 认证和 ACL(访问控制列表),提供端到端的数据加密和审计功能。
- 云原生集成:支持 Kubernetes 部署,并可与云存储服务(如 AWS S3)交互,实现混合云场景。
4. 应用场景与优势
Ozone 适用于多种场景,包括:
- 大数据分析:作为 Hadoop 和 Spark 的存储后端,支持复杂的数据分析工作流。
- AI/ML 平台:为机器学习模型训练提供高性能、低延迟的数据存取。
- 备份与归档:利用其高可靠性和低成本特性,用于长期数据存储。
总体而言,Apache Ozone 通过其灵活的架构和强大的生态集成,为现代数据处理和存储需求提供了高效的解决方案,是构建数据密集型应用的理想选择。